


Resources
Access our self-service portal to find tools, documentation, calculators, and everything else you need to get the most out of our services.
Self Service PortalAn open-source suite of tools and services for health data modelling, ontology management, and query definition, accessible via application or REST APIs.
Live Manager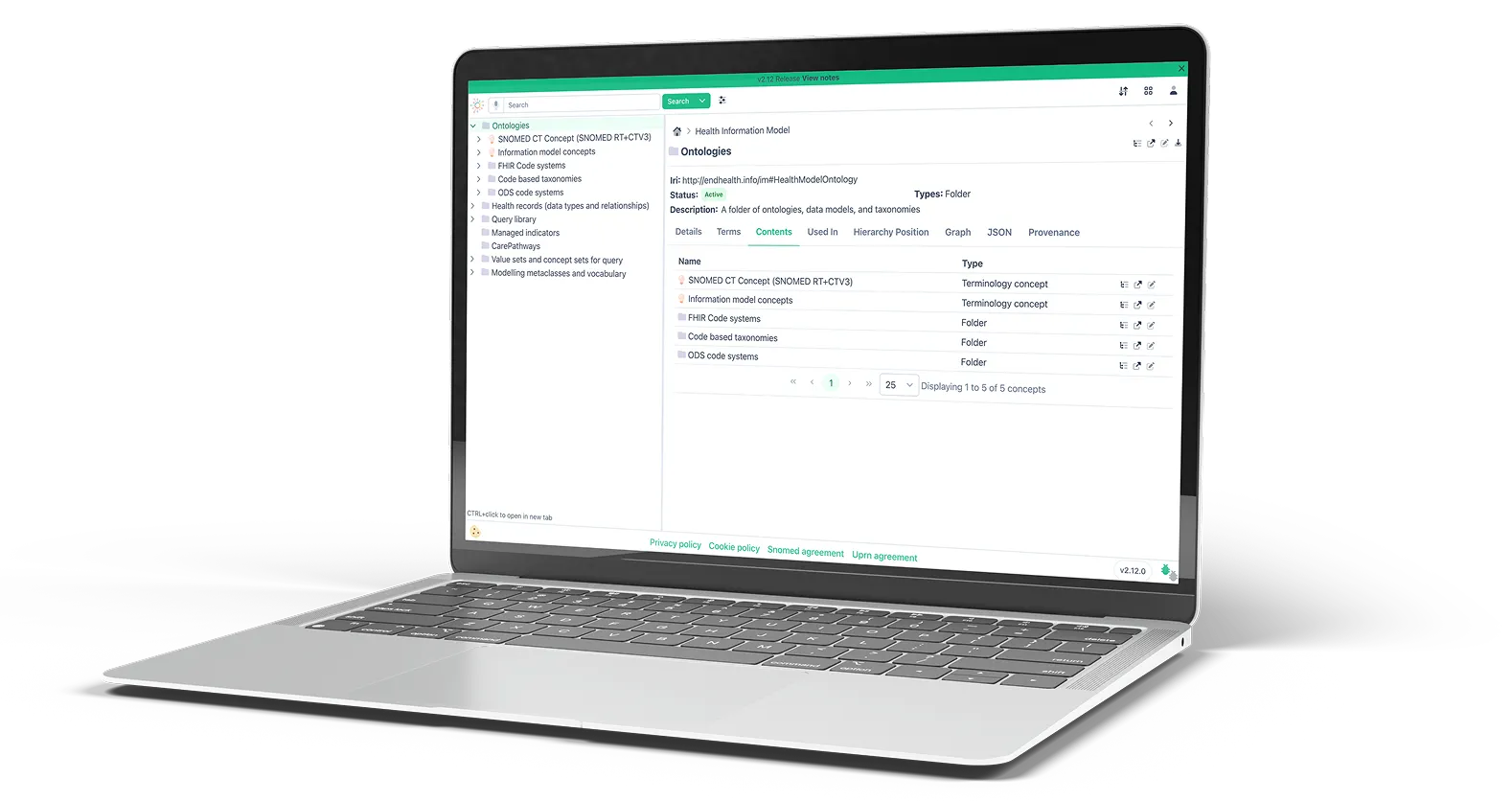
The Endeavour information manager is an extensive application and set of deployable services designed to help informaticians and software developers to understand health data, and provide utilities for data modelling, query definition, concept set definition and ontology servers.
In line with the charity’s philosophy the manager and services are made available as open-source, employing a wide range of technology platforms and languages including Graph database, Relational databases, SPARQL, Elastic, A Cypher-like DSL (IMQ), SQL, Java, Node JS with Vue as the front end framework.
A metadata and ontology service consisting of a super ontology of health ontologies, a set of data models, a set of taxonomy and structural maps, value sets and query definitions. These are made available either via an information manager application or via a set of RESTful APIs. The model is built using W3C semantic web standard languages such as RDF, RDFS, OWL2, SHACL, RML and SPARQL. See Information Model for more details.
Access our self-service portal to find tools, documentation, calculators, and everything else you need to get the most out of our services.
Self Service Portal

The Discovery Information Model is a representation of the meaning and structure of data held in the electronic health records that have been published to the Discovery data service. It consists of an ontology of ontologies, a common basic data model, a vocabulary of terms used in the ontology and data model, a set of maps between terms and codes, and a library of various sets for use in query or by the data models.
It is designed to help systems and informaticians make sense of the chaos of data from different systems. The model contents are accessed either by APIs or via an open-source application : Information Model Manager.
In order for machines to understand the content and structure, and to enable interoperability both within healthcare and with other sectors, it uses a set of international standard languages that form the languages of the semantic web.
It is not a single information model in the conventional sense. Nor is it a single data source. Whilst there is a single data model that encompasses the data, the expectation is that there is a need for as many data models as there are business requirements.
However, because the model uses a common vocabulary semantically defined using ontological techniques, computers that understand the vocabulary can interoperate even when using different data models. This is the basis for the semantic web.
Unlike human language, machine based languages must use logical constructs and once the means of using logic is understood then the computers can use the logic to process the data. The model does not own its ontology. Instead it absorbs the best ontologies and supplements with additional content not yet defined. In using the London extension of Snomed-CT, it can generate new concepts and expressions that can be shared across the NHS. Only those concepts that are necessary are created in order to prevent loss of detail.
